☰




ZooKeeper, while being a coordination service for distributed systems, is a distributed application on its own. ZooKeeper follows a simple client-server model where clients are nodes (i.e., machines) that make use of the service, and servers are nodes that provide the service. Applications make calls to ZooKeeper through a client library. The client library is responsible for the interaction with ZooKeeper servers. Below figure shows the relationship between clients and servers. Each client imports the client library, and then can communicate with any ZooKeeper node.

ZooKeeper servers run in two modes: standalone and quorum. Standalone mode is pretty much what the term says: there is a single server, and ZooKeeper state is not replicated. In quorum mode, a group of ZooKeeper servers, which we call a ZooKeeper ensemble, replicates the state, and together they serve client requests.
At any given time, one ZooKeeper client is connected to one ZooKeeper server. Each ZooKeeper server can handle a large number of client connections at the same time. Each client periodically sends pings to the ZooKeeper server it is connected to let it know that it is alive and connected. The ZooKeeper server responds with an acknowledgment of the ping, indicating the server is alive as well. When the client doesn't receive an acknowledgment from the server within the specified time, the client connects to another server in the ensemble, and the client session is transparently transferred over to the new ZooKeeper server.
A coordination service can be thought of, containing a list of primitives, also expose calls to create instances of each primitive, and manipulate these instances directly. But ZooKeeper does not expose primitives directly. Instead, ZooKeeper has a file system-like data model composed of znodes. Think of znodes (ZooKeeper data nodes) as files in a traditional UNIX-like system, except that they can have child nodes. Another way to look at them is as directories that can have data associated with themselves. Each of these directories is called a znode.
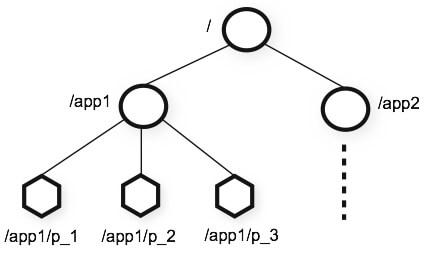
The name space provided by ZooKeeper is much like that of a standard file system. A name is a sequence of path elements separated by a slash (/). Every node in ZooKeeper's name space is identified by a path. Unlike is standard file systems, each node in a ZooKeeper namespace can have data associated with it as well as children. It is like having a file-system that allows a file to also be a directory. (ZooKeeper was designed to store coordination data: status information, configuration, location information, etc., so the data stored at each node is usually small, in the byte to kilobyte range.)
Znodes maintain a stat structure that includes version numbers for data changes, ACL changes, and timestamps, to allow cache validations and coordinated updates. Each time a znode's data changes, the version number increases. For instance, whenever a client retrieves data it also receives the version of the data.
The data stored at each znode in a namespace is read and written atomically. Reads get all the data bytes associated with a znode and a write replaces all the data. Each node has an Access Control List (ACL) that restricts who can do what.
The znode hierarchy is stored in memory within each of the ZooKeeper servers. This allows for scalable and quick responses to reads from the clients. Each ZooKeeper server also maintains a transaction log on the disk, which logs all write requests. This transaction log is also the most performance critical part of ZooKeeper because a ZooKeeper server must sync transactions to disk before it returns a successful response. The default maximum size of data that can be stored in a znode is 1 MB. Consequently, even though ZooKeeper presents a file system-like hierarchy, it shouldn't be used as a general-purpose file system. Instead, it should only be used as a storage mechanism for the small amount of data required for providing reliability, availability, and coordination to your distributed application.
The absence of data often conveys important information about a znode.
When creating a new znode, you also need to specify a mode. The different modes determine how the znode behaves.
A znode can be either persistent or ephemeral. A persistent znode /path can be deleted only through a call to delete. An ephemeral znode, in contrast, is deleted if the client that created it crashes or simply closes its connection to ZooKeeper.
Persistent znodes are useful when the znode stores some data on behalf of an application and this data needs to be preserved even after its creator is no longer part of the system.
Ephemeral znodes convey information about some aspect of the application that must exist only while the session of its creator is valid.
A sequential znode is assigned a unique, monotonically increasing integer. This sequence number is appended to the path used to create the znode. For example, if a client creates a sequential znode with the path /tasks/ task-, ZooKeeper assigns a sequence number, say 1, and appends it to the path. The path of the znode becomes /tasks/task-1. Sequential znodes provide an easy way to create znodes with unique names. They also provide a way to easily see the creation order of znodes.
To summarize, there are four options for the mode of a znode: persistent, ephemeral, persistent_sequential, and ephemeral_sequential.
Each znode has a version number associated with it that is incremented every time its data changes. A couple of operations in the API can be executed conditionally: setData and delete. Both calls take a version as an input parameter, and the operation succeeds only if the version passed by the client matches the current version on the server. The use of versions is important when multiple ZooKeeper clients might be trying to perform operations over the same znode.
Accessing a znode every time a client needs to know its content would be very expensive: it would induce higher latency and more operations to a ZooKeeper installation.Watches are a simple mechanism for the client to get notifications about the changes in the ZooKeeper ensemble.clients register with ZooKeeper to receive notifications of changes to znodes. Registering to receive a notification for a given znode consists of setting a watch. A watch is a one-shot operation, which means that it triggers one notification. To receive multiple notifications over time, the client must set a new watch upon receiving each notification.
In quorum mode, ZooKeeper replicates its data tree across all servers in the ensemble. But if a client had to wait for every server to store its data before continuing, the delays might be unacceptable. In public administration, a quorum is the minimum number of legislators required to be present for a vote. Similarly in ZooKeeper, it is the minimum number of servers that have to be running and available in order for ZooKeeper to work. This number is also the minimum number of servers that have to store a client’s data before telling the client it is safely stored. For instance, we might have five ZooKeeper servers in total, but a quorum of three. So long as any three servers have stored the data, the client can continue, and the other two servers will eventually catch up and store the data.
It is important to choose an adequate size for the quorum. For reliable ZooKeeper service, you should deploy ZooKeeper in a cluster known as an ensemble. As long as a majority of the ensemble are up, the service will be available. Because Zookeeper requires a majority, it is best to use an odd number of machines.
To understand what this means, let’s look at an example that shows how things can go wrong if the quorum is too small. Say we have five servers and a quorum can be any set of two servers. Now say that servers s1 and s2 acknowledge that they have replicated a request to create a znode /z. The service returns to the client saying that the znode has been created. Now suppose servers s1 and s2 are partitioned away from the other servers and from clients for an arbitrarily long time, before they have a chance to replicate the new znode to the other servers. The service in this state is able to make progress because there are three servers available and it really needs only two according to our assumptions, but these three servers have never seen the new znode /z. Consequently, the request to create /z is not durable.
To avoid this problem, in this example the size of the quorum must be at least three, which is a majority out of the five servers in the ensemble. To make progress, the ensemble needs at least three servers available. Using such a majority scheme, we are able to tolerate the crash of f servers, where f is less than half of the servers in the ensemble. For example, if we have five servers, we can tolerate up to f = 2 crashes. The number of servers in the ensemble is not mandatorily odd, but an even number actually makes the system more fragile. Say that we use four servers for an ensemble. A majority of servers is comprised of three servers. However, this system will only tolerate a single crash, because a double crash makes the system lose majority. Consequently, with four servers, we can only tolerate a single crash, but quorums now are larger, which implies that we need more acknowledgments for each request. The bottom line is that we should always shoot for an odd number of servers.






