☰




Because HBase tables can be large, they are broken up into partitions called regions. Each region server handles one or more of these regions. Now whether to read/write into a specific region, finding a region server which host that region is first step. Let us see how it is done.
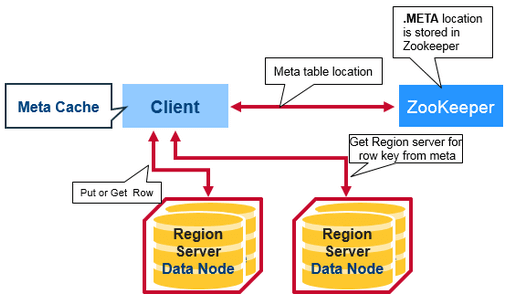
There is a special HBase Catalog table called the META table, which holds the location of the regions in the cluster. ZooKeeper stores the location of the META table.
Since the row key is sorted, it is easy to determine which region server manages which key. A change request is for a specific row. Each row key belongs to a specific region which is served by a region server. So based on the put or delete’s key, an HBase client can locate a proper region server. At first, it locates the address of the region server hosting the -ROOT- region from the ZooKeeper quorum.
From the root region server, the client finds out the location of the region server hosting the -META- region. From the meta region server, then we finally locate the actual region server which serves the requested region. This is a three-step process, so the region location is cached to avoid this expensive series of operations. If the cached location is invalid, it’s time to re-locate the region and update the cache.
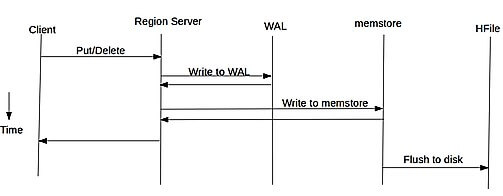
Once client finds region in HBase to write, the client sends the request to the region server which has that region for changes to be accepted. The region server cannot write the changes to a HFile immediately because the data in a HFile must be sorted by the row key. This allows searching for random rows efficiently when reading the data. Data cannot be randomly inserted into the HFile.
Instead, the change must be written to a new file. If each update were written to a file, many small files would be created. Such a solution would not be scalable nor efficient to merge or read at a later time. Therefore, changes are not immediately written to a new HFile.
Instead, each change is stored in a place in memory called the memstore, which cheaply and efficiently supports random writes. Data in the memstore is sorted in the same manner as data in a HFile. When the memstore accumulates enough data, the entire sorted set is written to a new HFile in HDFS.
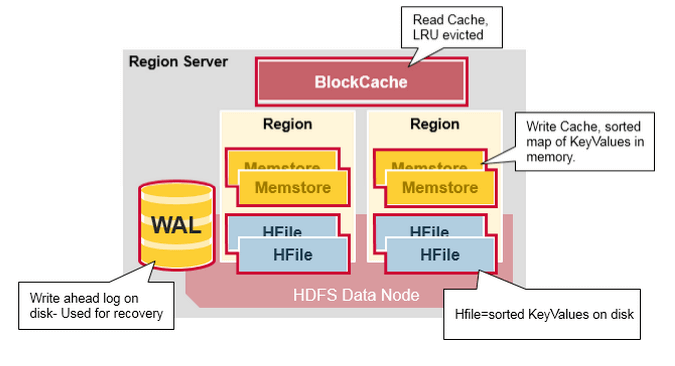
Although writing data to the memstore is efficient, it also introduces an element of risk: Information stored in memstore is stored in volatile memory, so if the system fails, all memstore information is lost. To help mitigate this risk, HBase saves updates in a write-ahead-log (WAL) before writing the information to memstore. In this way, if a region server fails, information that was stored in that server’s memstore can be recovered from its WAL.
WAL files contain a list of edits, with one edit representing a single put or delete. The edit includes information about the change and the region to which the change applies. Edits are written chronologically, so, for persistence, additions are appended to the end of the WAL file that is stored on disk.
As WALs grow, they are eventually closed and a new, active WAL file is created to accept additional edits. This is called rolling the WAL file. Once a WAL file is rolled, no additional changes are made to the old file. By default, WAL file is rolled when its size is about 95% of the HDFS block size.
A region server serves many regions, but does not have a WAL file for each region. Instead, one active WAL file is shared among all regions served by the region server. Because WAL files are rolled periodically, one region server may have many WAL files. Note that there is only one active WAL per region server at a given time.
Now you know what happens internally during Hbase write operation. Let us summarize the write process:
HBase read process starts when a client sends a request to Hbase. Once the request is sent, below steps are executed to read data from HBase.
When a Delete command is issued through the HBase client, no data is actually deleted. Surprised!!. What really happens during data deletion process ?
When a Delete command is issued through the HBase client, no data is actually deleted. Instead a tombstone marker is set, making the deleted cells effectively invisible. User Scans and Gets automatically filter deleted cells until they get removed.
The tombstone markers and deleted cells are only deleted during major compactions (which compacts all store files to a single one). Hence HBase periodically removes deleted cells during compactions.
There are 3 different types of internal delete markers.
When deleting an entire row, HBase will internally create a tombstone for each ColumnFamily (i.e., not each individual column). Deletes work by creating tombstone markers. For example, let’s suppose we want to delete a row. For this you can specify a version, or else by default the currentTimeMillis is used. What this means is delete all cells where the version is less than or equal to this version.
HBase never modifies data in place, so for example a delete will not immediately delete (or mark as deleted) the entries in the storage file that correspond to the delete condition. Rather tombstone is written, which will mask the deleted values. When HBase does a major compaction, the tombstones are processed to actually remove the dead values, together with the tombstones themselves. If the version you specified when deleting a row is larger than the version of any value in the row, then you can consider the complete row to be deleted.
Also, if you delete data and put more data but with an earlier timestamp than the tombstone timestamp, further gets may be masked by the tombstone marker. It only gets fixed after major compaction has run and hence you will not receive the inserted value till after major compaction in this case.


