☰




Storm exposes a set of primitives for doing realtime computation. Like how MapReduce greatly eases the writing of parallel batch processing, Storm's primitives greatly ease the writing of parallel realtime computation.The key properties of Storm are:
Storm is a distributed, reliable, fault-tolerant system for processing streams of data. The work is delegated to different types of components that are each responsible for a simple specific processing task. The input stream of a Storm cluster is handled by a component called a spout. The spout passes the data to a component called a bolt, which transforms it in some way. A bolt either persists the data in some sort of storage, or passes it to some other bolt. You can imagine a Storm cluster as a chain of bolt components that each make some kind of transformation on the data exposed by the spout. The arrangement of all the components (spouts and bolts) and their connections is called a topology.
A Storm cluster is superficially similar to a Hadoop cluster. Whereas on Hadoop you run "MapReduce jobs", on Storm you run "topologies". "Jobs" and "topologies" themselves are very different -- one key difference is that a MapReduce job eventually finishes, whereas a topology processes messages forever (or until you kill it).
There are two kinds of nodes on a Storm cluster: the master node and the worker nodes. The master node runs a daemon called "Nimbus" that is similar to Hadoop's "JobTracker". Nimbus is responsible for distributing code around the cluster, assigning tasks to machines, and monitoring for failures.
Each worker node runs a daemon called the "Supervisor". The supervisor listens for work assigned to its machine and starts and stops worker processes as necessary based on what Nimbus has assigned to it. Each worker process executes a subset of a topology; a running topology consists of many worker processes spread across many machines.
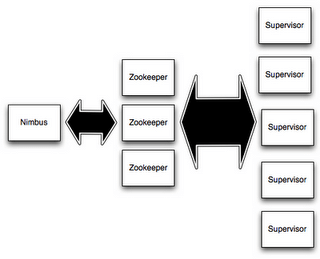
All coordination between Nimbus and the Supervisors is done through a Zookeeper cluster. Additionally, the Nimbus daemon and Supervisor daemons are fail-fast and stateless; all state is kept in Zookeeper or on local disk. This means you can kill -9 Nimbus or the Supervisors and they'll start back up like nothing happened. This design leads to Storm clusters being incredibly stable.
Basically, Storm cluster consists of one master node (called nimbus) and one or more worker nodes (called supervisors). In addition to the nimbus and supervisor nodes, Storm also requires an instance of Apache ZooKeeper, which itself may consist of one or more nodes.
Both the nimbus and supervisor processes are daemon processes provided by Storm and do not need to be isolated from individual machines. In fact, it is possible to create a single-node pseudo-cluster with the nimbus, supervisor, and ZooKeeper processes all running on the same machine.
The Nimbus node is the master in a Storm cluster. The nimbus daemon's primary responsibility is to manage, coordinate, and monitor topologies running on a cluster, including topology deployment, task assignment, and task reassignment in the event of a failure. Nimbus is stateless and stores all of its data in ZooKeeper. There is a single Nimbus node in a Storm cluster. It is designed to be fail-fast, so when Nimbus dies, it can be restarted without having any effects on the already running tasks on the worker nodes. This is unlike Hadoop, where if the JobTracker dies, all the running jobs are left in an inconsistent state and need to be executed again.
Deploying a topology to a Storm cluster involves submitting the prepackaged topology JAR file to the nimbus server along with topology configuration information. Once nimbus has received the topology archive, it in turn distributes the JAR file to the necessary number of supervisor nodes. When the supervisor nodes receive the topology archive, nimbus then assigns tasks (spout and bolt instances) to each supervisor and signals them to spawn the necessary workers to perform the assigned tasks.
Nimbus tracks the status of all supervisor nodes and the tasks assigned to each. If nimbus detects that a specific supervisor node has failed to heartbeat or has become unavailable, it will reassign that supervisor's tasks to other supervisor nodes in the cluster.
As mentioned earlier, nimbus is not a single point of failure in the strictest sense. This quality is due to the fact that nimbus does not take part in topology data processing, rather it merely manages the initial deployment, task assignment, and monitoring of a topology. In fact, if a nimbus daemon dies while a topology is running, the topology will continue to process data as long as the supervisors and workers assigned with tasks remain healthy. The main caveat is that if a supervisor fails while nimbus is down, data processing will fail since there is no nimbus daemon to reassign the failed supervisor's tasks to another node.
Supervisor nodes are the worker nodes in a Storm cluster. Each supervisor node runs a supervisor daemon that is responsible for creating, starting, and stopping worker processes to execute the tasks assigned to that node. Like Nimbus, a supervisor daemon is also fail-fast and stores all of its state in ZooKeeper so that it can be restarted without any state loss. A single supervisor daemon normally handles multiple worker processes running on that machine.
Both the supervisor daemon and the workers spawns are separate JVM processes. If a worker process spawned by a supervisor exits unexpectedly, the supervisor daemon will attempt to respawn the worker process.
In any distributed application, various processes need to coordinate with each other and share some configuration information. ZooKeeper is an application that provides all these services in a reliable manner. Being a distributed application, Storm also uses a ZooKeeper cluster to coordinate various processes. All of the states associated with the cluster and the various tasks submitted to the Storm are stored in ZooKeeper. Nimbus and supervisor nodes do not communicate directly with each other but through ZooKeeper. As all data is stored in ZooKeeper, both Nimbus and the supervisor daemons can be killed abruptly without adversely affecting the cluster.


